#GemmaSprint
huggingface : https://huggingface.co/joeykims/BEANs
github : https://github.com/GOOGLE-MLB-2024-GJ/Beans
Google MLB에서 마지막 프로젝트인 Gemma Sprint에서 gemma를 이용해 파인튜닝을 해보았습니다.
파인튜닝 주제는 커피에 대한 전반적인 지식과 커피 원두를 추천해주는 서비스입니다.
최초에는 사용자가 원하는 느낌대로 원두(블렌딩)을 해주는 서비스로 생각하고 시작하였으나,
자연스럽게 커피 대화도 오고갈 수 있을 것 같아서 그 부분까지 커버하려고 하였습니다.

모델
출시되지 오래되지 않은 2b 모델을 기반으로 파인튜닝을 진행하였습니다.
-.gemini 기본모델
(https://huggingface.co/google/gemma-2b-it)
처음에는 기본모델인 "google/gemma-2b-it"로 파인튜닝을 하다가, gemma 한국어 버전을 만들어 놓으신게 있어서 거기서 더 확장을 시도 하고 있습니다.
-.gemma 한국어 버전
https://huggingface.co/beomi/gemma-ko-2b
튜닝후 대화
어색한 부분이 아직 많은 느낌입니다. 데이터와 튜닝 파라미터를 조정해서 더 자연스럽게 만들어 볼 예정입니다.
(초창기에는 커피 전반적인 지식만 가지고 튜닝을 시작하였는데 향후에 맛을 기반으로 원두를 추천하는 데이터들도 넣어주었습니다, +2024/10/04)
데이터를 처음에 고민을 많이 하다가 인터넷에 공유되어 있는 커피 전반적인 지식을 하나씩 가져왔습니다. (약 2천개 가량)
그 후에 맛을 기반으로 추천을 해주는 데이터를 약 천개가량 추가하였습니다.
총 3200개 가량의 데이터로 튜닝을 진행하였습니다.
-.데이터 전처리
gpt로 적절히 finetunning 모델을 위한 구조로 데이터를 생성하게 하였습니다.
따로 gpt api를 쓰지 않았기 때문에 시간이 제법소요 되었습니다만, 나름 괜찮은 퀄리티의 데이터라고 생각하는 정도로 데이터를 생성하였습니다.
{ "instruction": "커피가 체중 감소에 도움을 줄 수 있는 이유는 무엇인가요?", "response": "커피 속 카페인이 신진대사를 촉진하고, 지방 연소를 촉진해 체중 감소에 도움이 될 수 있습니다.", "category": "closed_qa" },
{ "instruction": "항산화 성분이 풍부한 커피의 건강 효과는 무엇인가요?", "response": "커피에 포함된 항산화 성분은 세포 손상을 방지하고, 노화를 지연시키며, 암 예방에도 기여할 수 있습니다.", "category": "closed_qa" },
{ "instruction": "커피가 고혈압 환자에게 미치는 영향은 무엇인가요?", "response": "연구에 따르면, 하루 한 잔의 커피가 고혈압 환자의 혈관 탄력을 개선하여 혈관 경화를 방지하는 데 도움을 줄 수 있습니다.", "category": "closed_qa" },
{ "instruction": "커피가 뇌 건강에 미치는 긍정적인 효과는 무엇인가요?", "response": "커피 속 카페인은 도파민과 같은 신경 전달 물질의 분비를 촉진해 뇌 건강을 유지하고, 인지 기능을 향상시키는 데 기여합니다.", "category": "closed_qa" },
context도 원래는 있었는데 그다지 많이 쓰이지 않는 것같아서 Instruction과 response로 구성하였습니다.
자원
처음에 kaggle과 colab에서 진행을 하다가 개인 맥북프로가 더 빠를것 같아서 옮겼습니다.(두개다 파인튜닝을 하기에는 자원이 좀 모자르다는 생각이 들었습니다.)
이분의 코드를 바탕으로 수정을 하였습니다.
https://devocean.sk.com/blog/techBoardDetail.do?ID=165703&boardType=techBlog
여기서 맥북에서 하면 문제가 하나 있는데 트랜스포머가 4.38.2가 맥북에서 안돌아갑니다.
그래서 4.38.1로 다운해서 진행하였습니다.
https://www.singleye.net/2024/04/%E5%9C%A8-apple-silicon-m3-max-%E4%B8%8A%E5%AF%B9-llama2-%E8%BF%9B%E8%A1%8C%E5%BE%AE%E8%B0%83/#4-qlora-4-bit-%E9%87%8F%E5%8C%96%E9%85%8D%E7%BD%AE-m3-%E8%B7%B3%E8%BF%87
맥북프로 m3 기준으로 해서 2천개 데이터를 기준으로 한번할때 3시간 정도 소요됐던 것 같습니다.
gpu도 같이 돌려서 그런지 그나마 빠르게 진행 할 수 있었습니다.
(데이터를 3200개 가량 하였을때 9시간 ~ 11시간 가량 소요되었습니다. 데이터가 조금 늘어났는데 이상하게 많이 늘어난 느낌이네요)
macbook gpu 자원 사용은 아래의 내용을 참고하였습니다.
https://velog.io/@es_seong/Mac
파인튜닝
파인튜닝은 아래와 같은 설정으로 진행하였습니다. 맥이라서 양자화가 안되서 cpu로 진행을 하게 끔 하였고, 아래의 설정들을 잠시 살펴보자면
# LoRA 설정
lora_config = LoraConfig(
r=6,
lora_alpha=8,
lora_dropout=0.05,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
# 모델 설정
trainer = SFTTrainer(
model=model,
train_dataset=train_data,
max_seq_length=512,
args=TrainingArguments(
output_dir="outputs",
max_steps=3000,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
optim="adamw_torch",
warmup_steps=0.03,
learning_rate=2e-4,
fp16=False,
logging_steps=100,
push_to_hub=False,
report_to='none',
use_mps_device=False
),
peft_config=lora_config,
formatting_func=generate_prompt, # 새로운 포맷팅 함수 적용
)
아래의 설정들을 잠시 살펴보자면
r=6
: r은 랭크(rank)를 의미하며, LoRA에서 학습하는 저차원 행렬의 차원을 정의합니다. 이는 모델 파라미터의 효율적 표현을 가능하게 하며, 작은 r 값은 적은 학습 파라미터를 의미합니다. 일반적으로 r 값이 높을수록 더 많은 학습 파라미터를 가지게 되어 성능이 향상될 수 있지만, 메모리 사용량이 늘어납니다.
lora_alpha=8
: lora_alpha는 LoRA에서 사용하는 학습률을 조정하는 스케일링 팩터입니다. 이는 저차원 행렬에서 나온 출력을 조정하는 역할을 하며, 학습률의 크기를 결정짓는 중요한 요소입니다. 일반적으로 더 큰 값은 학습 속도를 높일 수 있지만, 너무 크면 과적합 위험이 있습니다.
lora_dropout=0.05
: lora_dropout은 드롭아웃 비율을 설정하며, 모델 학습 시 과적합을 방지하기 위해 일부 파라미터를 무작위로 제거하는 비율을 나타냅니다. 여기서는 5%의 드롭아웃이 적용됩니다.
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"]
: target_modules는 LoRA가 적용되는 모듈들을 지정합니다. 여기서는 q_proj, k_proj, v_proj 등 주로 Transformer 기반 모델에서 사용되는 쿼리, 키, 밸류 프로젝션 모듈에 LoRA가 적용됩니다. 이러한 모듈은 주로 어텐션 매커니즘에서 중요한 역할을 하며, 이 모듈들만 학습함으로써 학습 효율성을 높입니다.
task_type="CAUSAL_LM"
: task_type은 수행하려는 작업의 유형을 정의합니다. 여기서는 **Causal Language Modeling(CAUSAL_LM)**을 의미하며, 모델이 문맥을 기반으로 다음 단어를 예측하는 방식으로 학습됩니다.
성능
성능 평가는 추후에 다양한 방법으로 진행을 해볼 예정입니다.
모델 튜닝시에는 아래와 같이 진행되었습니다.

+ Perplexity 측정 결과
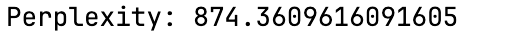
추가로 참고한 내용들
-.캐글에서 TPU로 파인튜닝
https://www.kaggle.com/code/alirezaebrahimi/gemma-2-tpu-fine-tuning
-.커피 관련된 데이터 베이스(원두의 맛을 점수로 나타냄, 데이터는 이것으로 하지 않음.)
https://github.com/ddthang86/Coffee-data-analysis/blob/main/Arabica/df_arabica_clean.csv
-.lora 공부한 곳